
Power Queryで「データの読み込みが終わらない」「複数のファイルを結合したら固まった」──そんな経験、ありませんか?
 はんちゃん(SE)
はんちゃん(SE)Power Queryって便利って聞いたのに、遅くてイライラする…」
 チャー
チャー実は、Power Queryが遅くなるのには、よくある“設計ミス”や“処理の順番”が原因かもしれません。
この記事では、Power Query初心者の方でもすぐに実践できる、遅くなる5つの代表的な原因と対策をやさしく解説します。
記事の最後には、すぐに使えるチェックリストもご紹介しているので、ぜひ最後まで読んでみてくださいね!
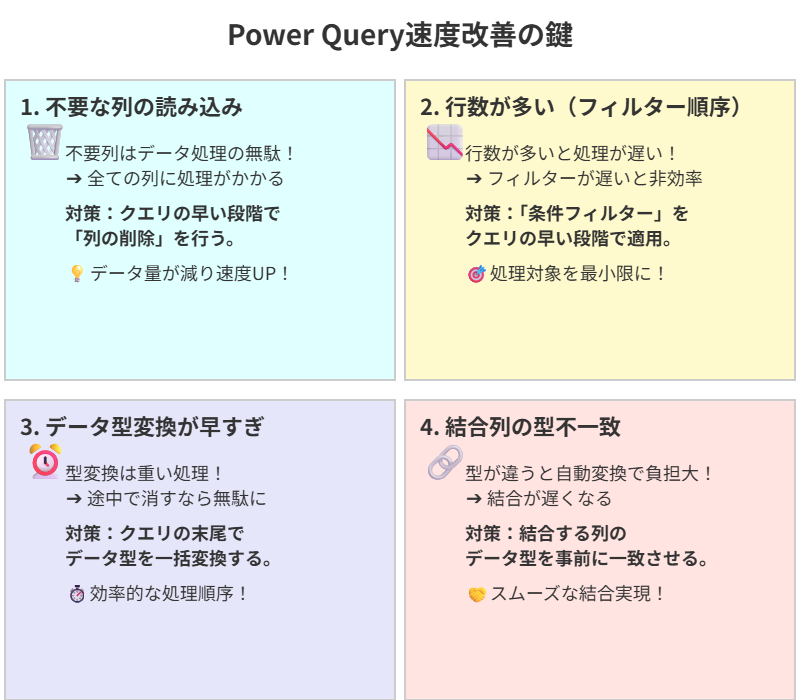
原因①:不要な列をそのまま読み込んでいる
Point: 必要な列だけに絞ると読み込みが速くなります。
Power Queryは、読み込んだデータすべての列にデータ型の判定や処理をかけます。
たとえば、100列あるデータからたった5列しか使わない場合でも、Power Queryは不要な95列に対しても処理を行ってしまうのです。
Action: クエリの早い段階で「列の削除」ステップを追加し、必要な列だけに絞り込みましょう。これだけで、全体の処理速度が大きく改善します。
原因②:行数が多すぎる(フィルターの順序が遅い)
Point: 先に行数を減らすだけで、全体の処理が速くなります。
クエリのステップは上から順番に実行されます。
そのため、行を減らすフィルター処理が後の方にあると、それまでのステップはすべてフルデータに対して実行されてしまいます。
たとえば、1万件のデータから500件だけを使う場合、最後のステップでフィルターをかけると、それまでのすべての処理が1万件のデータを対象に行われてしまうため、非常に非効率です。
Action: 「条件フィルター」はなるべくクエリの早い段階で追加し、処理対象となるデータ量を最小限に抑えましょう。
原因③:データ型の変換タイミングが早すぎる
Point: データ型の変換はクエリの最後にまとめて行うのが鉄則です。
データ型の変換は、Power Queryにとって負荷のかかる処理の一つです。
変換後にその列を削除したり、フィルターしたりすると、変換にかかった処理が無駄になってしまいます。
Action: データ型の変換は、クエリの末尾で一括で行うようにしましょう。これにより、無駄な処理を省き、パフォーマンスを向上させることができます。
原因④:結合する列のデータ型が一致していない
Point: 結合する列のデータ型を一致させると、パフォーマンスが大きく向上します。
「文字列」と「数値」のように、データ型が異なる列同士を結合(マージ)しようとすると、Power Queryは自動で型を変換しようとします。
この自動変換処理が大きな負担となり、処理速度を著しく低下させてしまうのです。
Action: 結合を行う前に、対象となる列のデータ型を必ず一致させてから実行しましょう。
これだけで、結合処理の時間が大幅に短縮されることがあります。
原因⑤:ネットワーク上の巨大なファイルを直接読み込んでいる
Point: ファイルをローカルに保存したり、データベースにリンクしたりすることで軽量化できます。
ネットワーク経由でデータソースにアクセスすると、通信速度がボトルネックとなり、処理が遅くなることがあります。
特にファイルサイズが大きい場合、データの読み込みだけでかなりの時間がかかってしまいます。
Action: サーバー上のExcelファイルなど、ネットワーク上のファイルを扱っている場合は、一度ローカルに保存して読み込んでみましょう。また、Accessなどのデータベースにリンクすることも有効な対策です。
まとめ|5つの原因をチェックしてPower Queryを快適に!
「なんかPower Queryが遅いな…」と感じたら、まずは今回ご紹介した5つのポイントをチェックしてみてください。
意外と**「処理の順番」や「ちょっとした設定の見落とし」**が原因だった、というケースは非常に多いです。

次回の予告
チャー次回は、特に質問が多い「結合(マージ)処理で遅くなる原因と対策」について、さらに詳しく解説します。どうぞお楽しみに!
コメント